We know that changing GPU rendering states during DrawCalls incurs overhead. Modern graphics APIs (D3D12, Vulkan, Metal) provide PSO mechanisms to reduce the overhead of hardware state changes. The principle is to merge shaders and rendering states required for a single render into one object, called a Pipeline State Object (PSO). The graphics API resolves dependencies and redundancies between various hardware states, provides the optimal state set and setup methods (called compilation), and then uniformly submits them to the hardware for setting rendering states.
However, PSO generation and compilation are expensive and can cause stuttering when processed at runtime. Considering that the rendering state combinations used by a program are predictable, information can be collected offline. Also, since PSOs are device-specific and can only be compiled on the device, a reasonable approach is to collect PSO lists offline and compile them at runtime. Additionally, since compiled PSOs can be reused, they can be cached in memory (Memory Cache) or serialized to disk (Binary Cache). This method is referred to as PSO Cache below.
UE encapsulates major rendering states into PSOs and provides a cache mechanism. The basic principle of PSO Cache is to collect all encountered PSOs during the testing phase, then package this list into the game. After the game starts, it compiles all PSOs and their bound shaders, caches them in memory or on disk, and uses them directly at runtime.
The following diagram shows UE's key PSO workflow:
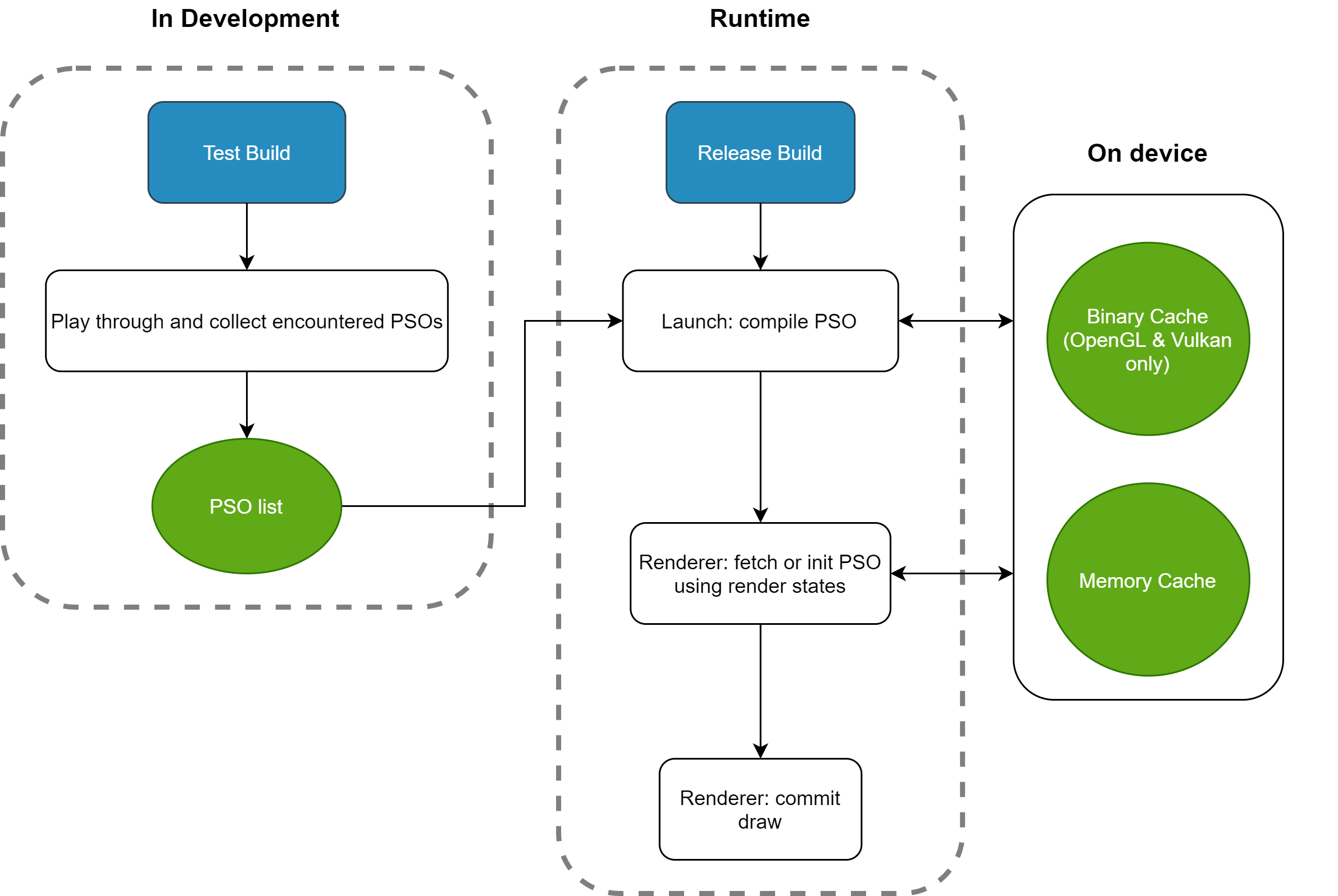
Note that three concepts need to be distinguished:
- Initial precompilation: When launching the game for the first time, compile all PSOs in the PSO list, which generates the rendering API's native cache. This is usually very slow.
- Subsequent precompilation (preloading): When launching the game subsequently, the precompilation process is still triggered, but since there's already a cache, the speed is greatly improved.
- Runtime loading: When submitting rendering, retrieve cached PSOs from memory or disk.
Although OpenGL doesn't support PSOs, it can still benefit from the shader precompilation mechanism that comes with the PSO Cache workflow. UE abstracts OpenGL's rendering states as PSOs, but what actually works is part of the PSO: BoundShaderState (BSS for short). The specific principle can be found in the analysis below.
Below, I'll first introduce PSO usage and optimization techniques, test performance, then analyze PSO implementation mechanisms, and propose optimization solutions.
Note: This article is based on version 4.26. Until the latest version of UE5, the core mechanism hasn't changed much, only the usage and APIs have slight modifications.
Basic Usage
Taking OpenGL ES 3.1 as an example
Recording
- First, the PSO feature requires the project to enable SharedCodeLibrary. Metal also recommends enabling NativeCodeLibrary. UE's default new project template has already enabled these two items.
- Before packaging the project, add the following configuration to AndroidEngine.ini:
[DevOptions.Shaders]
NeedsShaderStableKeys=true
- Enable r.ShaderPipelineCache.Enabled in the device configuration
- Launch the game with the -logpso parameter
- Run through all scenes
- Repeat the above scene running process several times to cover high-frequency scenes as much as possible
- During collection, results are automatically saved at intervals and after a certain quantity. You can also call console commands to force save. Results will be placed on the device at Saved/CollectedPSOs/*.rec.upipelinecache
Building
- Find Saved\Shaders\GLSL_ES3_1_ANDROID in the project directory and copy the csv files inside to a new folder (marked as [PSOCacheFolder])
- Find /mnt/sdcard/UE4Game/[project name]/[project name]/Saved/CollectedPSOs/ on the device, copy all rec.upipelinecache files from it, and place them in the [PSOCacheFolder] from step 2
- Enter [PSOCacheFolder] via command line and run the following command (modify the content in brackets):
UE4Editor-Cmd.exe [uproject path] -run=ShaderPipelineCacheTools expand ./*.rec.upipelinecache ./*.scl.csv ./[project name]_GLSL_ES3_1_ANDROID.stablepc.csv
- Place the stablepc.csv file generated in the previous step in the project directory under Build/Android/PipelineCaches
- Repackage. The packaging process will convert the above stablepc file to upipelinecache file and include it in the package
Running
- On first run, you can poll in the loading screen and call FShaderPipelineCache::NumPrecompilesRemaining to determine if PSOs have been compiled. Enter the game after compilation is complete. This precompilation process is triggered after splash and before loading UObjects. You can also disable precompilation at startup through compilation strategy and trigger it manually. See the "Compilation Strategy" section below for details.
- Compiled PSOs are cached in memory. OpenGL and Vulkan also cache to disk.
- When submitting rendering, cached and compiled PSOs are automatically utilized. Caches retrieved from both memory and disk show significant acceleration. Caches obtained from memory are faster.
Advanced Usage and Optimization
Using PSO according to the above method will significantly increase memory consumption and compilation time for slightly complex projects, and also burden the game's development and testing workflow. To solve this problem, UE provides many optimization methods.
Incremental Collection
The same game needs to run on multiple different devices and different quality options, and will continuously update resources, requiring multiple versions of PSOs. To cover all use cases, UE's PSO Cache supports incremental collection and can merge PSO Lists across Runs and Builds:
- Can merge rec.upipelinecache collected from different Runs of the same Build, thus obtaining data from multiple tests and improving scene running efficiency. To use this feature, place all rec.upipelinecache files in the same folder and generate the stablepc file together.
- Can merge stablepc files generated from different game versions and update the frequency of PSO occurrences using moving average. When game updates are not significant, this can reduce testing pressure, requiring only re-running updated parts for each update. To use this feature, retain the stablepc files generated from each Build, keep the platform name (e.g., GLSL_ES3_1_ANDROID) and suffix in the naming, place them in the same directory, and they will be automatically merged during Cook.
Using incremental collection can effectively improve PSO collection efficiency, allowing multiple tests to simultaneously collect data from different devices, quality settings, and maps, and also utilize historical data to improve PSO coverage.

Usage Mechanism
By default, the engine automatically merges all PSOs encountered in all Runs and also loads all PSOs by default at runtime, leading to increased startup time and memory usage. However, in a single run, most PSOs won't be used. To solve this problem, UE provides UsageMask, which marks different PSOs for different use cases.
- When recording PSOs, you can control what Usage all PSOs in the current Run should be marked as by setting r.ShaderPipelineCache.PreCompileMask
- You can use the SetGameUsageMaskWithComparison function to set the Usage to be recorded
- At runtime, you can selectively load PSOs belonging to a certain Usage (see next section)
Compilation Strategy
Based on combinations of several CVar configurations, PSO can support the following different compilation strategies:
- Full compilation at startup: All cooked PSOs are precompiled at startup. This is the engine's default method.
- Compilation by Usage at startup: Compile PSOs with specific UsageMask at startup (set via r.ShaderPipelineCache.PreCompileMask), requires enabling r.ShaderPipelineCache.GameFileMaskEnabled and r.ShaderPipelineCache.PreOptimizeEnabled
- Manual compilation by Usage: Manually call SetGameUsageMaskWithComparison to trigger compilation of custom UsageMask, requires enabling r.ShaderPipelineCache.GameFileMaskEnabled
Options 2 and 3 above can be used simultaneously. A typical usage is to allow the engine to compile some basic PSOs at startup to meet the needs of login screens, update screens, and other scenes. Subsequently, after determining the current device model and quality settings, load PSOs with the corresponding UsageMask. This mode can be seen in the following diagram:

Background Compilation
By default, the engine uses large batches for continuous compilation, which blocks the render thread. However, the engine also provides a background compilation mechanism: when compilation time exceeds a set threshold at startup, it switches to background compilation, compiling only 1 PSO per frame.
// Enable background compilation mode
r.ShaderPipelineCache.MaxPrecompileTime
// Limit the number of PSOs compiled per frame
r.ShaderPipelineCache.BackgroundBatchSize and r.ShaderPipelineCache.BatchSize
// Further limit the time used for compiling PSOs per frame
r.ShaderPipelineCache.BackgroundBatchTime and r.ShaderPipelineCache.BatchTime Used in conjunction with background compilation is PSO sorting settings. Options include: sorting by occurrence order, sorting by occurrence frequency, no sorting. Default is no sorting. Using appropriate sorting methods can reduce situations where PSOs aren't compiled in time.
LRU Mechanism
Because PSO creation is slow, Metal, OpenGL, and Vulkan PSOs all have runtime cache mechanisms, which cache generated PSOs in memory for the entire program runtime, allowing almost overhead-free reuse during rendering. However, when there are too many PSOs, especially with full precompilation, it brings significant memory consumption. OpenGL and Vulkan provide an LRU mechanism that can limit the number of PSOs loaded into memory. Related switches are r.OpenGL.EnableProgramLRUCache and r.Vulkan.EnablePipelineLRUCache. Metal currently has no similar mechanism.
After enabling LRU, you can further adjust LRU trigger conditions. There are two methods: limiting total PSO memory and limiting total PSO count. Once the limit is exceeded, the engine recycles the least recently used PSO. Related settings:
r.OpenGL.ProgramLRUCount
r.OpenGL.ProgramLRUBinarySize
r.Vulkan.PipelineLRUCapacity
r.Vulkan.PipelineLRUSizeOptimization Tips
- Use Usage. Usage can significantly alleviate memory issues caused by PSOs. Generally, using quality levels as UsageMask can eliminate quite a few PSOs at runtime. Additionally, consider adding device model and feature-related switches as extra mask bits. At runtime, avoid full compilation. You can use compilation strategy 2 above to load minimum quality PSOs at startup, then use compilation strategy 3 to load PSOs corresponding to current quality after entering the game, minimizing memory usage.
- Use LRU. If you can determine the maximum number of PSOs used simultaneously in the game, you can minimize stuttering by limiting PSO count. If there are hard memory targets, you can also limit PSO memory usage. However, if LRU size is set too low, it will cause in-game stuttering. Specific settings need to be determined through actual testing, balancing memory and performance.
- Continuous collection. Since the engine supports incremental collection across Builds, collected lists can be continuously retained. You can collect generated PSO Lists during functionality and adaptation testing (but don't collect during performance testing). This can improve PSO coverage and reduce in-game stuttering. You can also consider using scripts for automatic collection.
- Avoid compilation blocking the render thread. During compilation, the default BatchSize (50) is likely to completely block the render thread on low-end devices. You can adjust BatchTime and BatchSize to ensure users can see the compilation progress bar, otherwise users might think the program has frozen.
- Avoid using background compilation mode. For mobile platforms, if PSOs are continuously compiled in the background or uncompiled PSOs are encountered in-game, it will cause stuttering. Therefore, when startup time permits, mobile platforms should compile everything at once during startup or when switching quality settings, without using background compilation mode.
For the basis of the above optimization tips, see the performance testing below.
Performance Testing
Test Steps
- Build 1 empty map containing 1 sub-level that can trigger many PSOs
- After game startup, enter the empty map by default, then load the sub-level containing PSOs
- Record Stats with Dev package to observe PSO timing. Here we only record stuttering time during sub-level loading process, temporarily unable to be precise to each PSO's consumption
- Use Test package to observe overall memory situation, including three scenarios: empty map, full PSO map, re-entering empty map. Test the following configurations:
- Preload strategy: full, by Usage, no preload
- LRU: on and off
- Completely disable PSO
Runtime Settings
- Sub-level composition: Simple Mesh containing 512 PSOs (32 sub-materials × 4 Meshes × 2 light sources × 2 skylights)
- Quality options: Record 2 quality levels: HDR, LDR.
- PSO count: Record a total of 1024 material PSOs. Additionally, engine default materials, UI, etc. add another 30-40 PSOs. The actual number of PSOs used in scenes is around 512 (256 for Dev package).
- LRU settings: Engine defaults (Vulkan: 10MB, 2048; OpenGL: 35MB, 700)
- Async PSO: Vulkan and Metal enabled by default
- Test devices:
- OpenGL/Vulkan: Galaxy A6s
- Metal: iPhone 6
Test Results
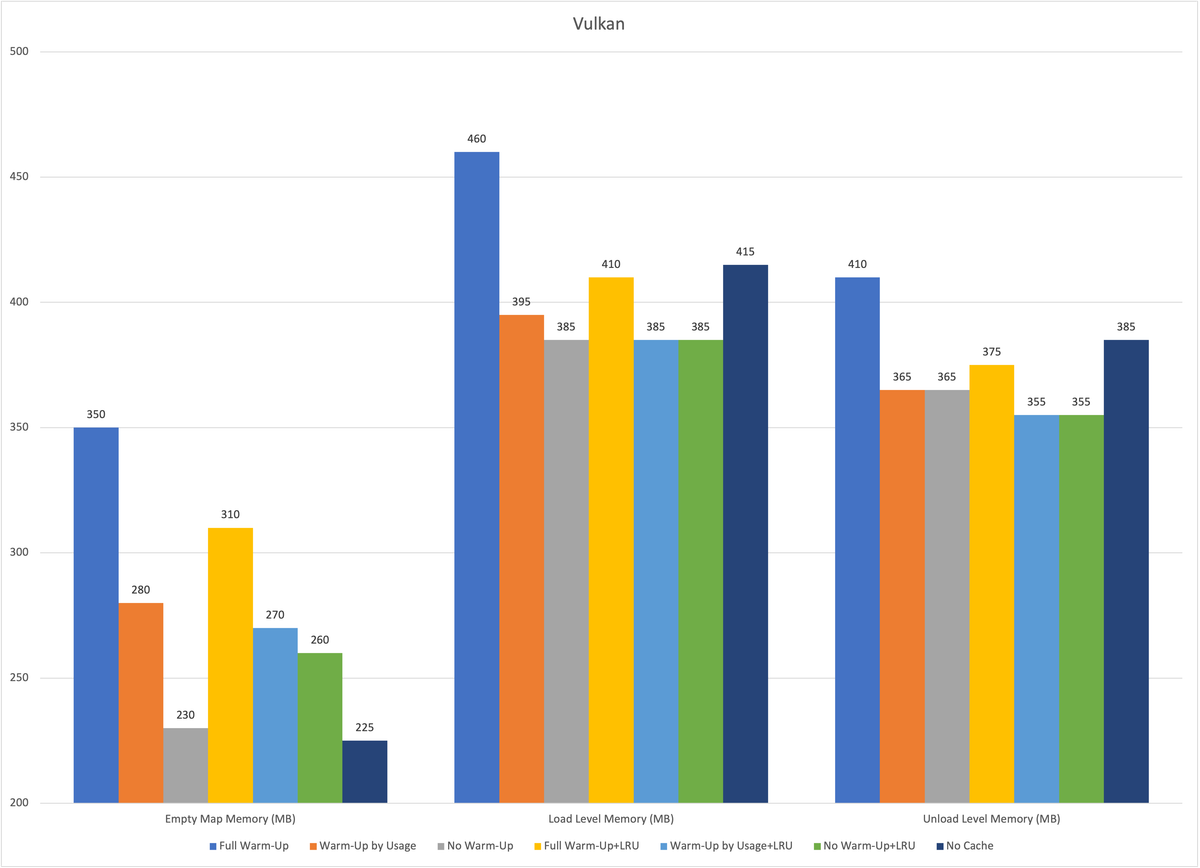
Memory Usage



PSO Loading Time

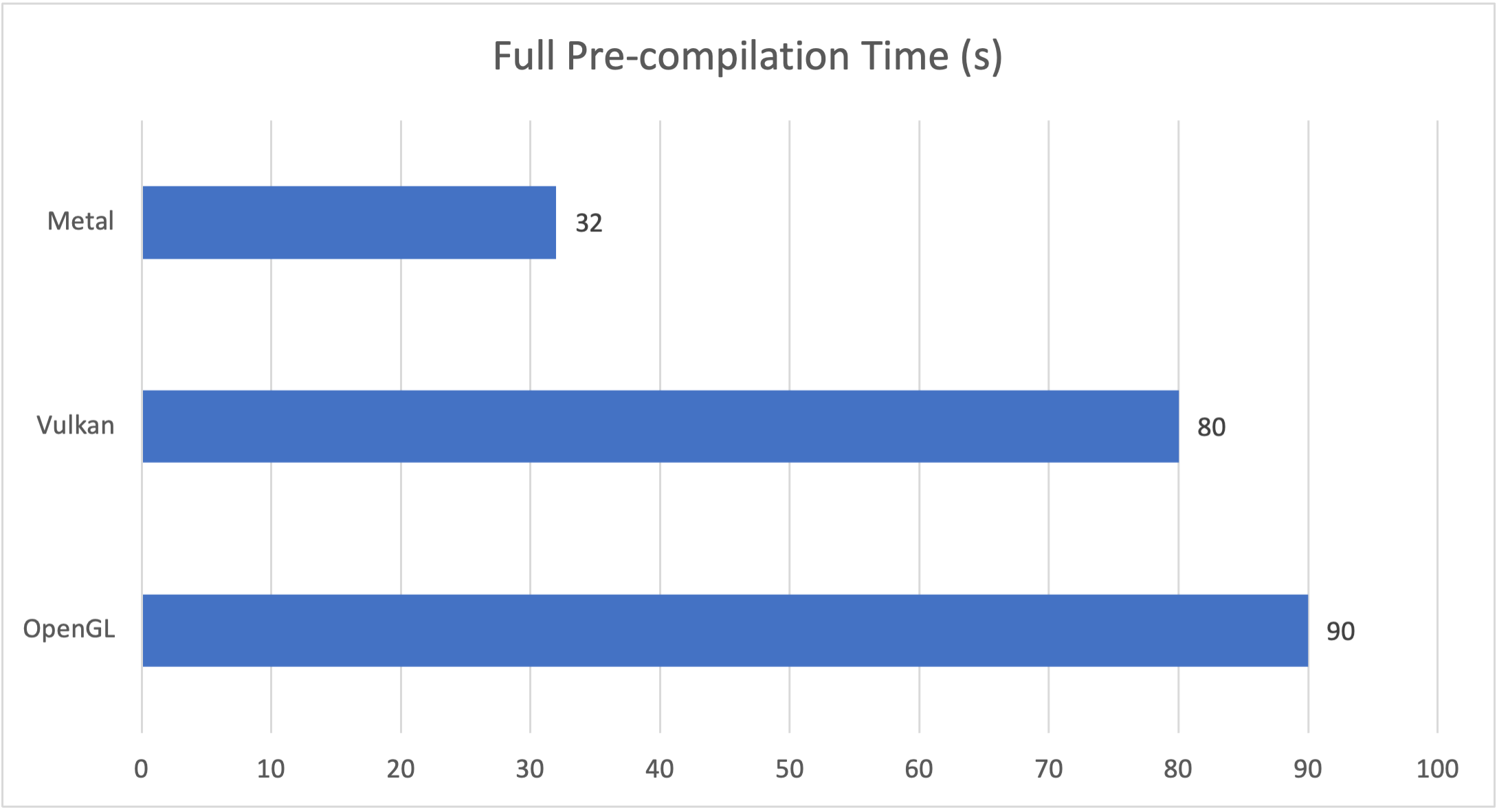
Initial Precompilation Time
Conclusions
- PSO Cache benefits:
- PSO Cache can reduce rendering startup latency by an order of magnitude on all platforms
- The memory consumption of the PSO Cache module itself is minimal and negligible
- For individual PSOs, without PSO Cache enabled, runtime PSO creation actually increases memory consumption
- Precompilation time is quite long on all platforms
- Android:
- On Android, each PSO brings 0.1MB-0.16MB memory consumption, with very high memory usage when fully loaded
- After Vulkan and OpenGL unload levels, PSO-related memory is not released
- iOS:
- Compared to Vulkan and OpenGL, Metal's PSO optimization is better, doesn't occupy excessive memory, and has low loading latency
- Usage and LRU:
- After using Usage, memory usage decreases significantly
- After enabling LRU, memory decreases somewhat, but loading performance declines
- Enabling LRU on top of Usage results in some memory reduction, but not significantly
- Preload optimization:
- Disabling subsequent precompilation after initial precompilation can save a lot of initial memory. OpenGL performance decline is more obvious, Vulkan and Metal decline is not significant, but overall each PSO's consumption is within 1ms
Implementation Mechanism
UE has three types of PSOs: Graphics, Compute, and RayTracing. Below we only introduce Graphics PSO.
UE4's Graphics PSO caches the following information:
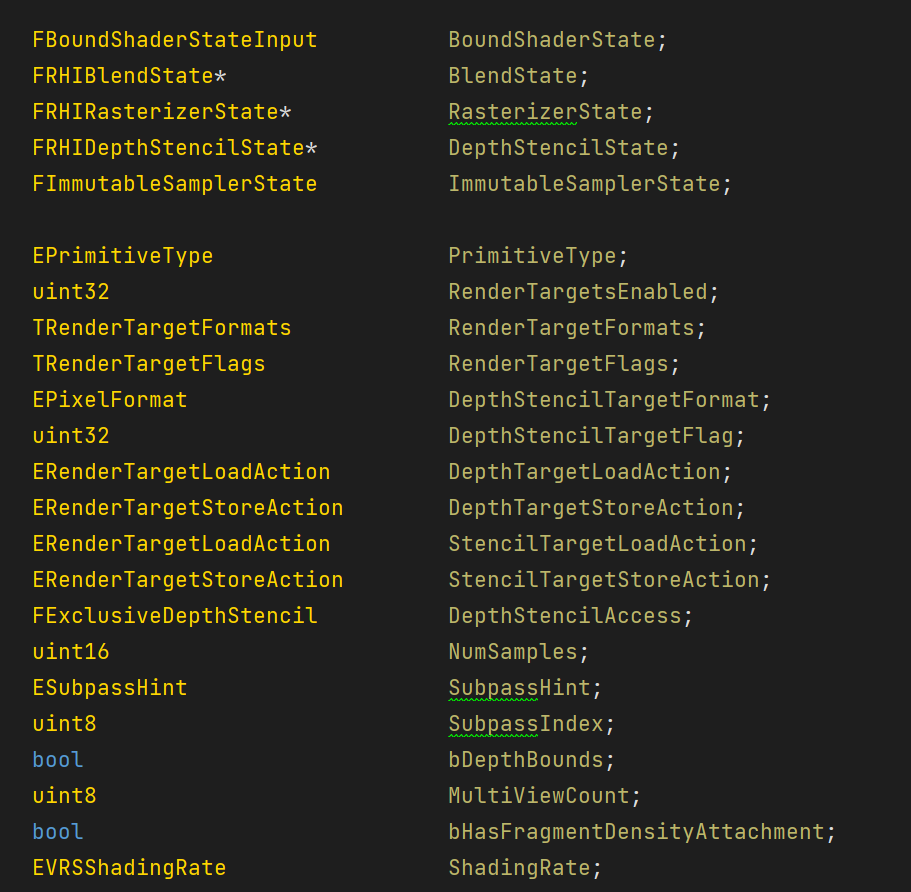
Among them, FBoundShaderStateInput (BSS) includes:
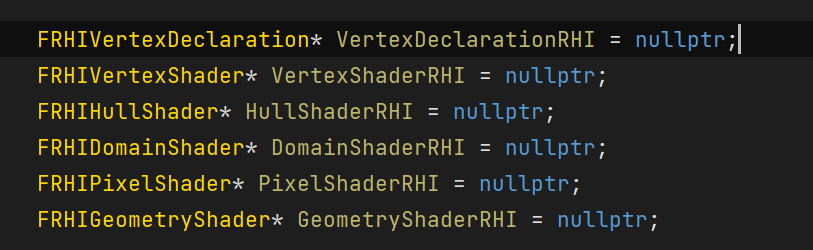
Depending on the platform, only part of the above information may be submitted as PSO, with the rest using fallback settings.
Key Classes
- UShaderPipelineCacheToolsCommandlet: Responsible for various processes in the PSO generation phase during Cook. Key functions include ExpandPSOSC (merging collected rec.upipelinecache and generating stablepc), and BuildPSOSC (merging stablepc and generating upipelinecache for runtime use)
- FShaderPipelineCache: Belongs to the RenderCore module, is the external interface for PSO functionality, responsible for managing PSO's external interface and lifecycle, including opening, compiling, saving, closing, etc. During initialization, it creates a global ShaderPipelineCache instance, registers as a RenderThread Tickable object, and triggers a batch of compilation each frame during Tick
- FPipelineFileCache: Belongs to the RHI module, is the RHI backend of FShaderPipelineCache, and is the main body of PSO functionality, mainly responsible for recording PSO data. Users don't use this class directly but should go through FShaderPipelineCache's interface. This global singleton loads with FShaderPipelineCache and initializes an FPipelineCacheFile object when loading
- FPipelineCacheFile: Belongs to the RHI module, represents a PSO Cache list file, responsible for serialization-related functionality of that list
- FGraphicsPipelineStateInitializer: Generated by each drawable component's (such as Mesh) Proxy, encapsulates various rendering states needed for rendering, used to initialize and index PSOs
- FGraphicsPipelineState: Obtained by Renderer calling GetAndOrCreateGraphicsPipelineState, handed to RHI for initialization
- FRHIGraphicsPipelineState: The RHI backend of FGraphicsPipelineState, driver-related, responsible for PSO compilation and submission. Different platforms have different implementations.
Runtime Overall Flow
Overall, it can be divided into three stages:
- Initiate precompilation: Occurs within the FShaderPipelineCache::Tick function. This process also triggers shader prefetching in ShaderCodeLibrary. Only PSOs with completed prefetching enter the compilation stage
- Precompilation and preloading: Occurs within the SetGraphicsPipelineState function. The actual work is completed in RHICreateGraphicsPipelineState. After completion, it's cached in the global GGraphicsPipelineCache. Subsequently, RHISetGraphicsPipelineState is called to complete initialization.
- Runtime loading: Also occurs within the SetGraphicsPipelineState function. First, rendering components collect pass-independent PSO states when building DrawCommands, storing them in FGraphicsMinimalPipelineStateInitializer. When submitting drawing, combined with pass-related information, a complete FGraphicsPipelineStateInitializer is generated, which is used to index, obtain, and initialize PSOs, finally submitting PSOs through RHISetGraphicsPipelineState.
As we can see, the final processes for precompilation (preloading) and actual PSO usage are the same, both calling the SetGraphicsPipelineState function. The difference is that during precompilation (preloading), PSO compilation and initialization are triggered by obtaining and setting PSOs without actual drawing occurring, so it doesn't include complete FGraphicsPipelineStateInitializer information.

Implementation Differences Between Different RHIs
| PSO Backend | Index Information | Async Compilation | Native Cache | |
|---|---|---|---|---|
| Metal | FMetalGraphicsPipelineState | Complete | Supported | None |
| Vulkan | FVulkanRHIGraphicsPipelineState | Complete | Supported | FVulkanPipelineStateCacheManager |
| OpenGL | FRHIGraphicsPipelineStateFallBack | BSS only | Not supported | FOpenGLProgramBinaryCache |
OpenGL is special because it doesn't have PSO support itself; what actually works is glProgram. Therefore, OpenGL's "PSO compilation" actually occurs during glProgramLink, which is in RHISetGraphicsPipelineState. Additionally, since glProgram is only shader-related, its PSO index only contains BSS information, meaning it uses the same index for compilation and runtime. This explains the phenomenon in the test results above where OpenGL platform's performance improvement after using preload is higher than other platforms.
Optimization Solutions
Problem Analysis
Based on the above analysis, the main problems with the PSO mechanism are:
- PSO compilation takes too long: When compiling PSOs for the first time, even temporarily unused PSOs are initialized, which takes considerable time, especially noticeable on low-end devices.
- Android's native cache doesn't update: For OpenGL and Vulkan, all Binary Caches are only generated during compilation and aren't updated afterwards. If PSO collection wasn't comprehensive or new PSOs are dynamically generated at runtime, it causes stuttering.
- Android lacks async compilation mechanism: OpenGL stutters when encountering new PSOs
For PC and console platforms, or small to medium mobile games, these issues have minimal impact. However, for large mobile games with many resources and a wide range of target device configurations, performance issues easily arise. To solve these problems, we can approach from the following aspects:
More Granular UsageMask
The existing PSO collection process collects all data into one file and loads the entire file at runtime. Although UsageMask and LRU are provided, they can't solve the problem of excessive compilation time. We need more granular PSO division methods. A reasonable approach is to divide by level, placing PSO loading during each level's loading, thereby reducing perceived waiting time for users and distributing memory pressure across different maps.
Completely Cancel PSO Preloading
OpenGL and Vulkan's PSO mechanism mainly relies on locally generated Binary Cache for acceleration. Metal, with its good async compilation mechanism, isn't significantly impacted by reduced preloading. Therefore, on low-end devices, consider completely canceling PSO preloading.
- Save a completion list during precompilation, and only trigger uncompiled parts when subsequently opening PSOs.
- Avoid ShaderLoad triggering streaming loading of BinaryCache.
According to the test results above, even if PSO preloading is subsequently disabled after compilation is complete, it won't cause severe performance loss.
Async PSO
Unreal Engine has some basic support for async PSO compilation, but it's not fully implemented. In a future article, I will discuss the implementation of async PSO compilation in detail.